隨著大數據技術的發(fā)展,實時數據處理已成為現代企業(yè)數據處理架構的重要組成部分。Apache Kafka和Apache Flume作為兩款主流的開源數據處理工具,在實時數據流處理中發(fā)揮著關鍵作用。它們各自具有獨特優(yōu)勢,并能夠通過集成實現更高效的數據處理流程。
一、Apache Kafka的核心特性
Apache Kafka是一個分布式流處理平臺,專為高吞吐量、低延遲的實時數據流設計。它基于發(fā)布-訂閱模式,能夠處理海量數據流,并確保數據的可靠傳輸。Kafka的主要特性包括:
- 高吞吐量:支持每秒數百萬條消息的處理。
- 持久化存儲:數據可持久化到磁盤,避免數據丟失。
- 分布式架構:支持水平擴展,適合大規(guī)模數據處理。
- 容錯性:通過副本機制保證數據的高可用性。
Kafka常用于日志聚合、事件源處理和實時流處理等場景。例如,在電商平臺中,Kafka可用于實時收集用戶行為數據,并傳輸給下游分析系統(tǒng)。
二、Apache Flume的核心功能
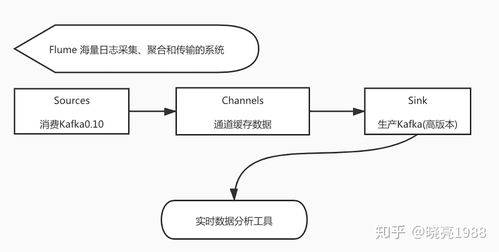
Apache Flume是一個分布式、可靠的日志收集系統(tǒng),專注于數據采集和傳輸。它適用于從多種數據源(如日志文件、社交媒體流)收集數據,并將其傳輸到存儲系統(tǒng)(如HDFS、HBase)。Flume的核心組件包括:
- Source:數據源,負責接收數據。
- Channel:數據通道,作為緩沖區(qū),保證數據傳輸的可靠性。
- Sink:數據目的地,將數據傳輸到目標系統(tǒng)。
Flume的優(yōu)勢在于其靈活的數據源支持和可靠的數據傳輸機制。例如,在日志監(jiān)控系統(tǒng)中,Flume可用于實時收集服務器日志,并將其導入HDFS進行長期存儲和分析。
三、Kafka與Flume的集成應用
雖然Kafka和Flume在功能上有重疊,但它們在實際應用中常被結合使用,以發(fā)揮各自優(yōu)勢。典型的集成模式包括:
- Flume作為數據采集層,從多種數據源收集數據,并通過Kafka Sink將數據發(fā)送到Kafka集群。
- Kafka作為數據緩沖層,接收Flume傳輸的數據,并提供高吞吐量的數據流處理。
- 下游系統(tǒng)(如Spark Streaming或Flink)從Kafka消費數據,進行實時分析和處理。
這種集成架構的優(yōu)勢在于:
- 靈活性:Flume支持多種數據源,而Kafka提供統(tǒng)一的數據流平臺。
- 可靠性:通過Flume的Channel和Kafka的副本機制,確保數據不丟失。
- 擴展性:兩者均支持分布式部署,適合處理大規(guī)模數據。
四、實時數據處理的最佳實踐
在實際應用中,構建高效的實時數據處理流程需注意以下幾點:
- 數據格式標準化:確保數據在Flume、Kafka和下游系統(tǒng)間采用一致的格式(如Avro、JSON)。
- 監(jiān)控與告警:部署監(jiān)控工具(如Prometheus)來跟蹤數據流性能,并及時發(fā)現異常。
- 資源規(guī)劃:根據數據量預估Kafka集群和Flume代理的資源配置,避免瓶頸。
- 安全性:通過SSL/TLS加密數據傳輸,并實施訪問控制策略。
五、總結
Apache Kafka和Apache Flume是實時數據處理生態(tài)中的關鍵組件。Kafka擅長高吞吐量的數據流處理,而Flume專注于靈活的數據采集。通過將它們集成,企業(yè)可以構建可靠、可擴展的實時數據處理管道,滿足日志分析、事件監(jiān)控和流式計算等多種需求。隨著技術的演進,Kafka和Flume將繼續(xù)在實時數據領域發(fā)揮重要作用,助力企業(yè)實現數據驅動的決策與創(chuàng)新。